


Robinhood case study (sentiment)
Planning Robinhood’s Response to the GameStop Debacle (sentiment analysis) Try it! Set in 2021, the Robinhood case tracks the sentiments expressed via Twitter as Robinhood (the
Accessibility Tools
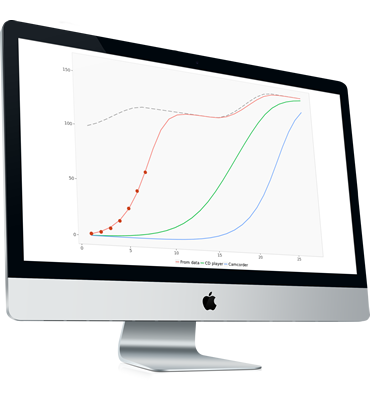

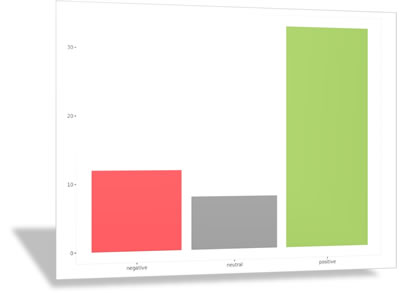
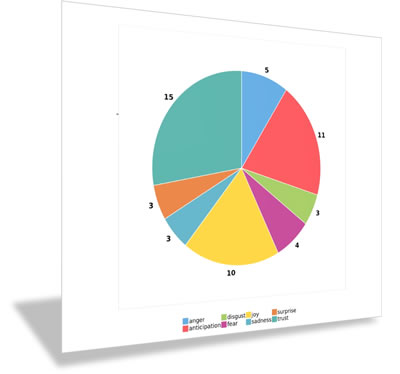

Planning Robinhood’s Response to the GameStop Debacle (sentiment analysis) Try it! Set in 2021, the Robinhood case tracks the sentiments expressed via Twitter as Robinhood (the
Mobile Games (sentiment analysis) Try it! Set in 2014, Mobile Apps is a case about the mobile app games market. It requires the application of